Inferring using Prompt Engineering
(A topic from Prompt Engineering course by Deep Learning.ai)


Inferring means deducing or concluding using some evidence or reasoning. In terms of AI, inferring is also known as making decisions based on available information or data. A Machine Learning model takes input and performs some analysis such as extracting labels, extracting topics, understanding the sentiment of the text etc. A traditional sentiment analysis using ML workflow requires you to collect a labeled data set, train the model, deploy the model in the cloud to make it accessible and finally use it to make some inferences and for every different task such as summarizing, extracting etc we have to train and deploy a separate model.
However, in Large Language Model(LLM) we can just write a prompt for such tasks and it starts inferring from the text provided. This gives speed up in application development. We can also use just one model or one API to do different tasks rather than training and deploying different models for each task.
For sentiment analysis, we have taken a single review of the movie 'Oppenheimer'.

We write a prompt to get the sentiment of the movie review.

We got the output as a statement however for post-processing it is convenient to get the output in one word. We ask here to provide output in only one word 'positive' or 'negative'.

LLMs are good at extracting specific things out of a piece of text which is a part of Natural Language Processing(NLP).

This can also be used to ask some questions regarding the review. In the below example, we want to know whether the writer of the review is angry or not.

Here we ask the question that whether the writer of the review will recommend the movie to others.

Here we are trying to extract some information from the text such as the movie name, what it depicts, and what is it based on.
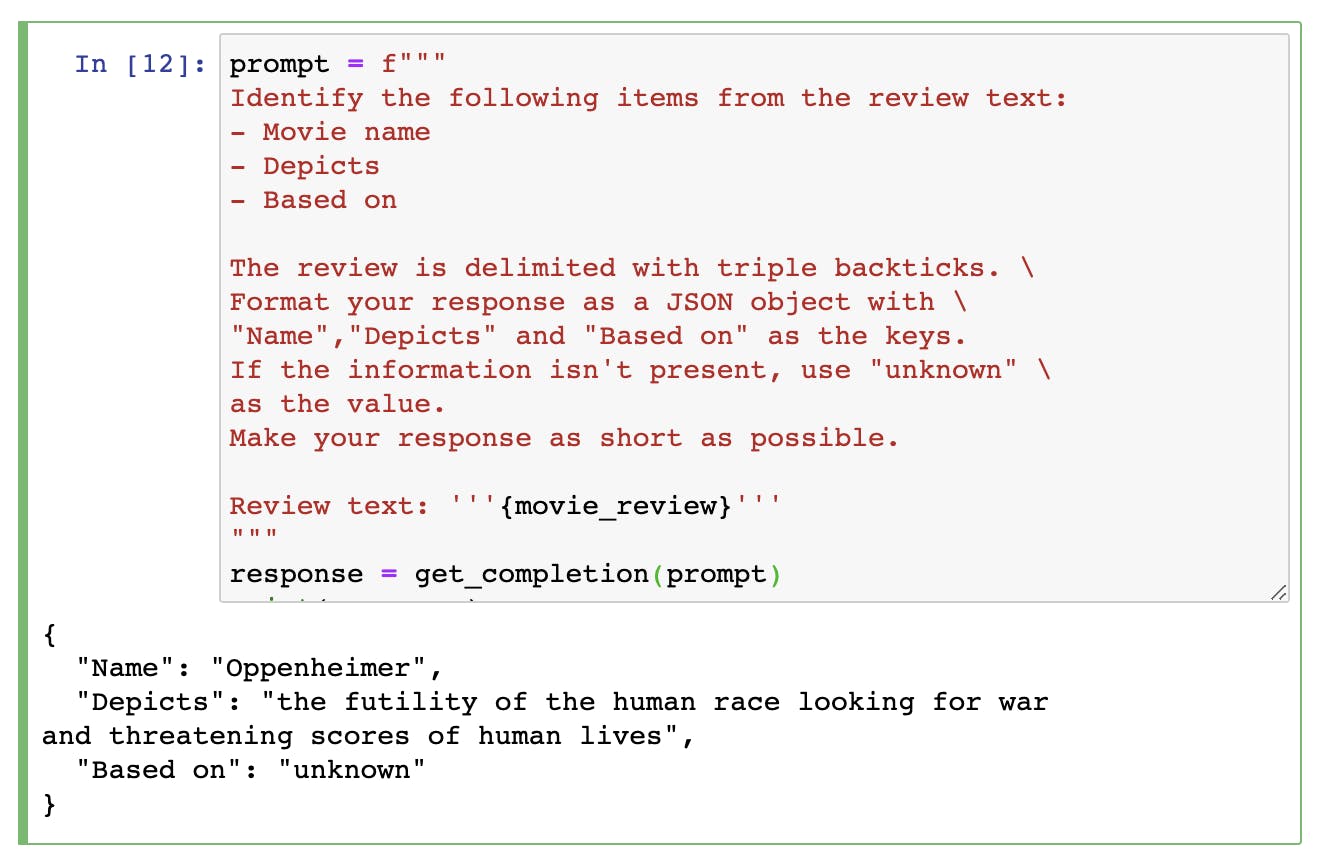
We can perform all the tasks with just one prompt.

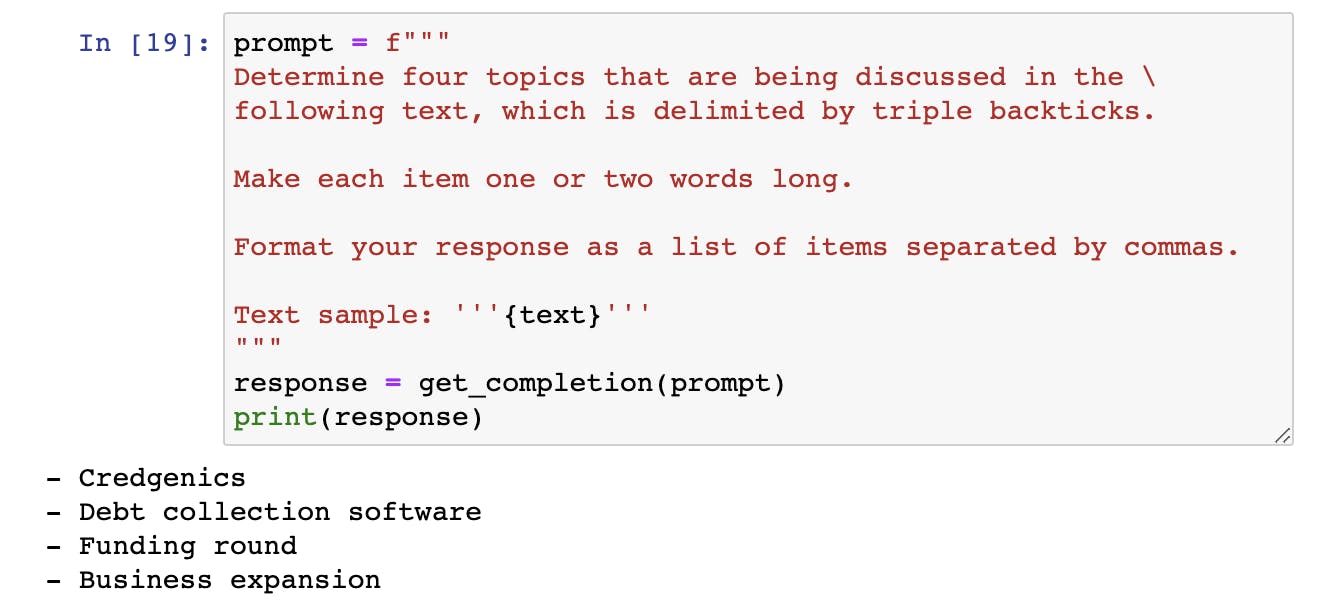
Next, we see another application of inferring i.e. to extract topics from a large piece of text.

We extract four different topics from the above text.
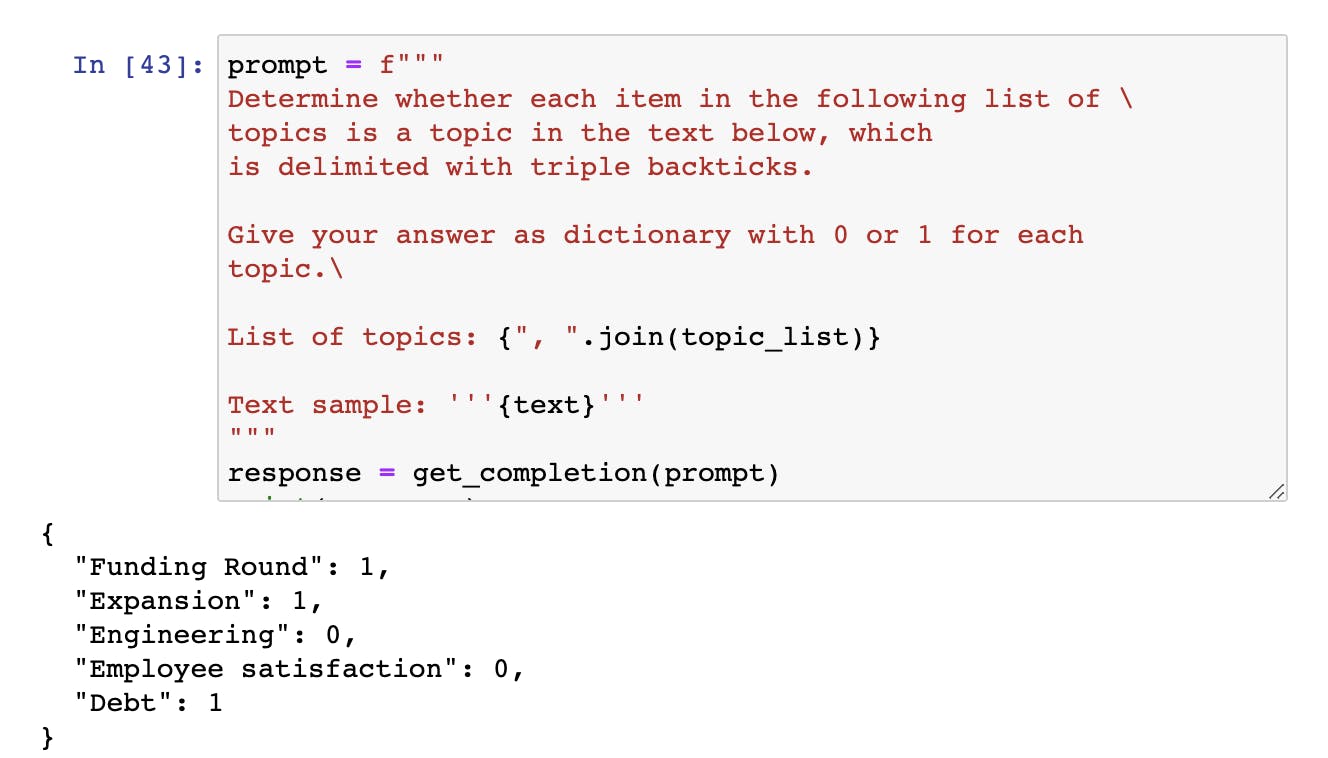
Next, we provide a list of possible topics and ask the model to predict what could be the possible topics for the above text in terms of a dictionary.

Thus we can build multiple systems for making inferences about the text that previously just would have taken days to be built by traditional ML methods.